
SuperPowers:Claude Codeの開発ワークフローを変えるプラグイン
Claude Code用プラグイン「SuperPowers」の導入方法と主要スキルを解説。brainstorming(設計)、TDD(テスト駆動開発)、サブエージェント並列開発など、AIコーディングの品質を体系的に引き上げる仕組みを、ソースコードに基づいて詳しく紹介します。

Claude Code用プラグイン「Ponytail」を題材に、SessionStartフックとスキルで「一度言っただけでは忘れられる指示」をAIエージェントへ注入する仕組みを実際のフックコードから解説。過剰実装を抑える「はしご」型プロンプト設計と、自作ルールへ転用できる汎用パターンも分解します。
注意: 本記事は2026年7月2日時点のPonytail v4.8.4に基づいています。オープンソースプロジェクトのため、最新の仕様は公式リポジトリをご確認ください。ベンチマーク数値も同リポジトリの計測結果を引用したものです。
「YAGNIで、最小限のコードでお願い」とAIエージェントに伝えたのに、日付入力のためだけにライブラリを追加し、ラッパーコンポーネントを作り、タイムゾーンの議論を始めた。そんな経験はないでしょうか。
あるいは、セッションの最初に「シンプルに」と念押ししたはずが、会話が長くなるにつれて指示が忘れられ、いつのまにか抽象化の層が積み上がっていく。Claude Codeを日常的に使う開発者なら、心当たりがあるかもしれません。
問題は、AIが「シンプルに書く」方法を知らないことではありません。知ってはいるのです。それでも、会話のターンが進むと最初の一言は文脈の奥へ押し流され、モデルは元の「なんでも作り込む」癖へ戻っていきます。一度きりの指示は、効き目が持続しないのです。
Ponytailは、この「指示が持続しない」問題に構造的に対処するClaude Code用のオープンソースプラグインです。MITライセンスで公開されています。本記事では、Ponytailがどうやって指示を「常時効く状態」に変えているのかを、実際のフックコードに基づいて解説します。
同じくClaude Codeの挙動を拡張するプラグインとして、以前SuperPowersを紹介しました。設計思想の違いが対比として面白いので、あわせて読むと理解が深まります。
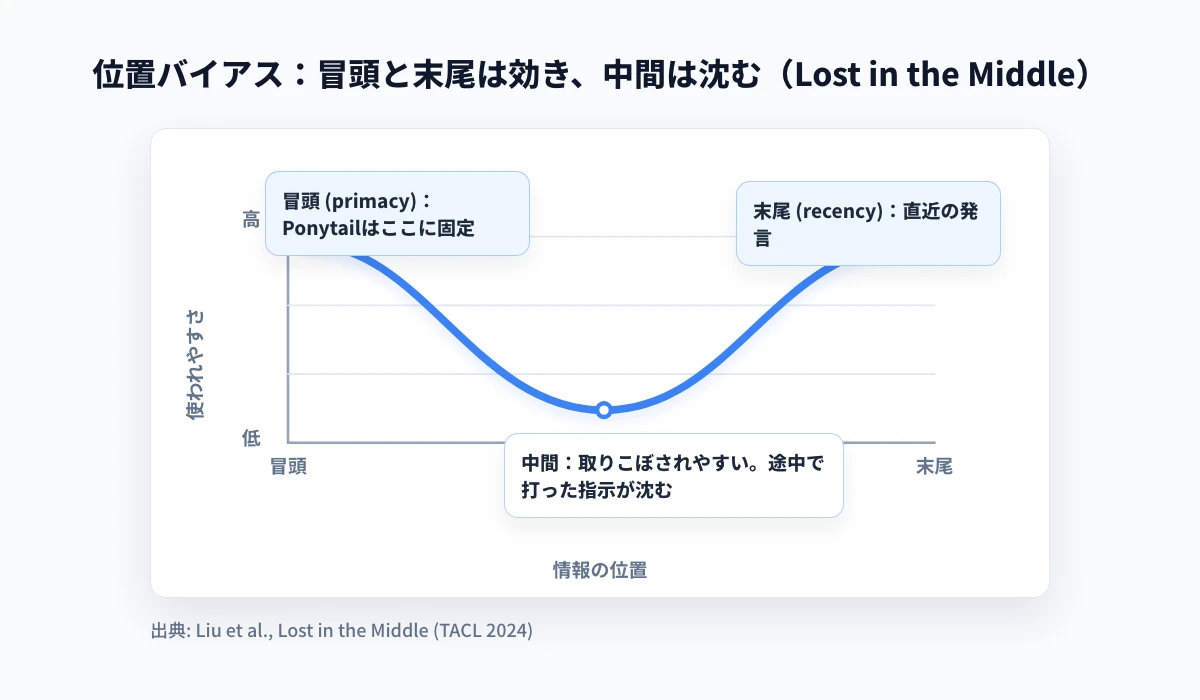
LLMは、入力のどの位置にある情報かによって、その使われやすさが変わります。Nelson Liuらの研究「Lost in the Middle」は、モデルが 入力の冒頭と末尾にある情報を最もよく使い、中間にある情報を取りこぼしやすい というU字型の傾向を報告しています(Lost in the Middle: How Language Models Use Long Contexts(TACL 2024))。会話が長くなると、序盤に一度打った「最小限で」という指示は、後続の何十ターンものやり取りに挟まれて次第に"中間"へ沈み、相対的に効きにくくなっていきます。
さらに、多くのモデルには「丁寧に、網羅的に応答しよう」とする傾向があります。頼まれてもいないエラーハンドリングの選択肢を並べ、設定可能なオプションを増やし、将来を見越した抽象化を先回りで用意する。善意なのですが、受託開発やプロダクト開発の現場では、この「先回りの作り込み」がそのまま保守コストになります。
つまり必要なのは、「シンプルに」という指示を 最も参照されやすい冒頭に固定し、会話全体に残し続ける仕組みです。人間が毎回リマインドするのは非現実的なので、ここを自動化するのがPonytailのアプローチです。
Ponytailは、AIエージェントに「怠惰なシニア開発者」を憑依させるプラグインです。ここでの「怠惰」は手抜きではなく効率を指します。あらゆる過剰設計のコードベースを見てきて、その尻拭いで深夜に呼び出された経験のあるベテランが、50行を見て何も言わず1行に置き換える。そんな人格をAIの中に常駐させます。
公式リポジトリのベンチマークによると、実際のオープンソースリポジトリ(FastAPI + Reactのフルスタックテンプレート)を対象に、同じエージェントでスキルあり・なしを比較した結果、以下が報告されています(Haiku 4.5、12タスク、n=4)。
| スキルなしとの比較 | コード量 | トークン | コスト | 時間 | 安全性 |
|---|---|---|---|---|---|
| Ponytail | -54% | -22% | -20% | -27% | 100% |
削減幅が最も大きいのは「本当に過剰実装しがちな場面」で、たとえば日付入力を404行から23行(ネイティブの<input type="date">を使う)まで削ったケースが報告されています。一方、もともと最小限のコードにはほとんど効きません。
ここで誠実だと感じるのは、公式リポジトリが以前公表していた「80〜94%削減」という単発生成ベースの数値について、「素のモデルの回答は前置きや選択肢で水増しされており、その差は会話ベースライン特有のもの」と自ら認め、公平なエージェント比較での平均54%へ数値を訂正・公開している点です。ベンチマークを扱う姿勢として参考になります。
そして重要なのは、削減の対象が 検証・エラーハンドリング・セキュリティ・アクセシビリティではないことです。これらは「怠惰にしてはいけない領域」として明確に線引きされています。コードが小さくなるのは、不要なものを書かないからであって、必要なものを削るからではありません。
ここからが技術的な本題です。Ponytailはどうやって指示を「常時効く状態」にしているのでしょうか。答えは Claude CodeのSessionStartフックにあります。
Claude Codeのフックは、特定のタイミングでスクリプトを実行できる拡張ポイントです。PonytailはSessionStart(会話開始時)にスクリプトを差し込み、そこでルール全文をコンテキストへ注入します。実際のフック本体hooks/ponytail-activate.jsの冒頭コメントに、その役割が明記されています。
#!/usr/bin/env node
// ponytail — Claude Code SessionStart activation hook
//
// Runs on every session start:
// 1. Writes flag file at $CLAUDE_CONFIG_DIR/.ponytail-active (defaults to ~/.claude; statusline reads this)
// 2. Emits ponytail ruleset as hidden SessionStart context
// 3. Detects missing statusline config and emits setup nudge処理は3ステップです。注目すべきはステップ2の「Emits ponytail ruleset as hidden SessionStart context」、つまり ルールセットを会話の先頭に、通常の会話履歴には表示されない形で送り込む部分です(コメント中の"hidden"はPonytail側の表現です)。SessionStartフックの出力は、会話の最初のプロンプトより前にコンテキストとして挿入されます。先頭に置かれたルールはその後の会話にそのまま残るため、以降のすべての応答にわたってAIの挙動へ影響し続けます。実行本体はおおよそ次のような流れになっています。
const mode = getDefaultMode();
// "off" mode — skip activation entirely, don't write flag or emit rules
if (mode === 'off') {
clearMode();
const hookOutput = (isCodex || isCopilot) ? '' : 'OK';
writeHookOutput('SessionStart', 'off', hookOutput);
process.exit(0);
}
// 1. Write flag file
try {
setMode(mode);
} catch (e) {
// Silent fail -- flag is best-effort, don't block the hook
}
// 2. Emit the ponytail ruleset, filtered to the active intensity level.
let output = getPonytailInstructions(mode);
// 3. ...(statusline検出ロジック)...
writeHookOutput('SessionStart', mode, output);設計上のポイントが2つあります。1つ目は、mode === 'off'のガードを先頭に置き、オフ時はフラグもルールも一切出力せず即座に終了すること。2つ目は、フラグ書き込みをtry/catchでサイレントに握りつぶしていることです。フラグはステータスライン表示用の付随機能なので、そこが失敗しても「フックがエラーでセッションが始まらない」事態を避ける、堅牢さ優先の判断です。
ここが「一度きりの指示」との決定的な違いです。会話の途中でユーザーが「シンプルに」と打っても、その一言はターンが進むほど履歴の奥へ押し流されていきます。一方フックは、セッションが始まるたびにルール全文をコンテキストの先頭へ据えます。先頭に固定され、以降の会話に残り続けるからこそ、ターンが進んでも指示がドリフトしにくいわけです。
ここで当然の疑問が湧きます。フックはセッションの開始時に1回動くだけなのに、なぜ10ターン、20ターンと進んだ後の応答にまで効き続けるのでしょうか。ここを理解するには、まず「セッション」と「メッセージ」を分けて考える必要があります。セッションとは、claude(や対応する他のエージェント)を起動してから終了するまでの1本の会話プロセスで、その中に多数のメッセージ(「ユーザーの入力 + AIの応答」の1往復)を含みます。そしてSessionStartフックは、メッセージごとではなく セッションの先頭で1回だけ発火します。
鍵になるのは、LLMがステートレスであるという事実です。LLM本体は前のやり取りを覚えているわけではありません。Anthropicの公式ドキュメントは次のように明記しています。
The Messages API is stateless, which means that you always send the full conversational history to the API.(Messages APIはステートレスであり、常に会話履歴の全体をAPIへ送信する)
出典: Using the Messages API(Claude Docs)
つまりメッセージを送るたびに、クライアント(Claude Code)が 会話履歴を丸ごと毎回モデルへ再送しています。モデルは毎回、渡された全履歴を読み直して応答を返しているだけです。3ターン目を送るときに実際にモデルへ渡されるのは、次のようなイメージです。

Claude Codeのフックでは、SessionStartの出力は additionalContext としてシステムリマインダーにラップされ、会話の最初のプロンプトより前に挿入されます(Hooks reference(Claude Docs))。チャットのメッセージとしては表示されませんが、Claudeは以降のモデル呼び出しでこれを読み続けます。したがってフックが毎ターン動いているのではなく、1回置かれたテキストを Claude Code が会話開始時のコンテキストとして保持し、以降の呼び出しに含め続ける。これが「後のメッセージにも効く」正体です。
会話の途中でユーザーが打った「シンプルに」も履歴には残りますが、その位置は会話の中ほどで、ターンが増えるほど大量の後続やり取りに埋もれて相対的に薄まります。先ほどの「Lost in the Middle」でいえば、最も取りこぼされやすい"中間"に沈んでいくわけです。SessionStart注入は逆に、最も参照されやすい冒頭(primacy)に固定され、しかも新しいセッションのたびに自動で入り直すため、ぶれにくいのです。
ただし、これは純粋に機械的な保証ではありません。会話が長くなってコンテキストが要約(compaction)されると、注意が薄れる可能性は残ります。PonytailのSKILL.md冒頭に Persistence: ACTIVE EVERY RESPONSE(毎レスポンスで有効、過剰実装に戻るな)という念押しが置かれているのは、履歴上の位置だけに頼らず、プロンプトの言葉でも drift を抑えにいく二重構えだと読めます。
Ponytailにはlite / full(デフォルト)/ ultraという強度レベルがあります。面白いのは、レベルごとに別々のスキルを持つのではなく、1つのスキル本文から送信するテキストを削る方式を取っている点です。hooks/ponytail-instructions.jsのfilterSkillBodyForModeがその実装です。
function filterSkillBodyForMode(body, mode) {
const effectiveMode = normalizeMode(mode) || DEFAULT_MODE;
const withoutFrontmatter = String(body || '').replace(/^---[\s\S]*?---\s*/, '');
// Only the intensity table rows and worked examples are mode-specific, and
// both are keyed by a mode name (lite/full/ultra). A bullet whose label is
// not a mode — e.g. "No unrequested abstractions: ..." — is a normal rule
// and must be kept verbatim.
return withoutFrontmatter
.split(/\r?\n/)
.filter((line) => {
const tableLabel = line.match(/^\|\s*\*\*(.+?)\*\*\s*\|/);
if (tableLabel) {
const labelMode = normalizeMode(tableLabel[1].trim());
if (labelMode) return labelMode === effectiveMode;
}
const exampleLabel = line.match(/^-\s*([^:]+):\s*/);
if (exampleLabel) {
const labelMode = normalizeMode(exampleLabel[1].trim());
if (labelMode) return labelMode === effectiveMode;
}
return true;
})
.join('\n');
}前提を押さえると分かりやすくなります。このSKILL.mdは、ほとんどが全モード共通の内容(「はしご」やルール群)です。モードごとに変えたい部分は一箇所、「Intensity」という節にある強度の比較テーブルと、モード別の応答例だけです。テーブルは各モードを1行ずつ並べた作りになっています。
(SKILL.md の Intensity 節。モード別なのはこの数行だけ)
| <strong>lite</strong> | Build what's asked, but name the lazier alternative … |
| <strong>full</strong> | The ladder enforced. Stdlib and native first. … |
| <strong>ultra</strong> | YAGNI extremist. Deletion before addition. … |filterSkillBodyForModeの仕事は、共通部分はそのまま残し、モード別の行からは現在のモードに一致するものだけを残して、他モードの行を捨てることです。たとえば full で注入するなら full の行だけ残り、lite と ultra の行は消えます。
では「モード別の行」をどう見分けるか。行の先頭ラベルがモード名(lite / full / ultra)かどうかを、2本の正規表現で判定するだけです。対象はテーブル行 | <strong>full</strong> | … | と、箇条書きの例 - full: … の2種類。ラベルがモード名でない行(=普通のルール)は判定を素通りして常に残ります。設定ファイルもパーサも持ち込まず、正規表現2本で済ませる。この割り切りそのものが「怠惰」な設計です。
さらにgetPonytailInstructionsは、スキルファイルが読めなかったときのためにgetFallbackInstructionsというハードコードされた代替文を用意しています。ファイルI/Oが失敗しても最低限のルールが必ず注入される、というフェイルセーフです。「常時効かせる」という目的に対して、抜け道を丁寧に塞いでいるのがわかります。
注入されるルールの中身も、プロンプトエンジニアリングとして見どころがあります。中心にあるのが「はしご(ladder)」と呼ばれる意思決定モデルです。コードを書く前に、上から順に「最初に成立する段」で止まる、というルールです。
<input type="date">)
この設計が巧みなのは、抽象的な「シンプルに」を 具体的なチェックリストに落とし込んでいる点です。「シンプルに」だけではモデルの解釈に幅が出ますが、「まず存在を疑い、次に再利用を探し、標準ライブラリ、ネイティブ機能、と順に見ていく」という手順に変換すると、判断がぶれにくくなります。
同時に、はしごには「問題を理解する前に登るな」という但し書きが添えられています。最小の差分を狙うあまり、影響範囲を読まずに間違った場所を直せば、それは2つ目のバグになる。「怠惰さは解の長さを縮めるのであって、理解の深さを縮めるのではない」という線引きが、明示的にルール化されています。
スキル定義のフロントマターも、プロンプト設計の一部です。
---
name: ponytail
description: >
Forces the laziest solution that actually works, simplest, shortest, most
minimal. ... Also use whenever the user
says "ponytail", "be lazy", "lazy mode", "simplest solution", "minimal
solution", "yagni", "do less", or "shortest path", or complains about
over-engineering, bloat, boilerplate, or unnecessary dependencies. Do NOT
use for non-coding requests (general knowledge, prose, translation,
summaries, recipes).
argument-hint: "[lite|full|ultra]"
license: MIT
---descriptionは単なる説明ではなく、このスキルをいつ発火させるかのトリガー条件を自然言語で定義したものです。「"yagni"や"do less"と言われたら起動する」「一方で翻訳や要約など非コードの依頼には使うな」という発火・除外の両方が、この1フィールドに収められています。指示の「持続」をフックが担い、指示の「発火条件」をスキルのメタデータが担う、という役割分担になっているわけです。
Ponytailの本質は「怠惰キャラ」そのものより、フックとスキルを組み合わせて、AIエージェントに任意のルールを常時効かせるという汎用パターンにあります。
たとえば自社の開発規約、命名規則、レビュー観点、禁止パターンなどを、会話のたびに手で貼り付けている場合、それをSessionStartフックからの注入に置き換えられます。ルールの本文はスキルのSKILL.mdに書き、フックはそれを毎回コンテキストへ流し込むだけ。強度の出し分けが要らなければ、PonytailのfilterSkillBodyForModeのような加工すら省けます。
このパターンは、モノレポのような大規模プロジェクトでClaude Codeを本格的に使い込むほど効いてきます。プロジェクトごとの制約をフックで固定化する具体例は、以前の記事でも触れました。
Ponytailが示すのは、突き詰めれば「AIに何をどう指示し続けるか」の設計です。ツールやモデルを変えるより、この「指示の設計」を整えるほうが、同じ環境でも成果を大きく左右します。Ponytailは、その設計を各自が毎回貼り直さずに済むよう、プラグインとして固定化した一例だと言えます。
弊社がチームのAI導入を支援するときも、力を入れているのはまさにここです。どんなルールを、どの層(フック・スキル・共通プロンプト)に固定すれば、個人の使い方に依存せずチーム全体で安定して効くのか。この「指示の設計と仕組み化」を一緒に組み立てるのが、単発のプロンプト指南より効いてきます。
Ponytailから学べることを整理します。
「フック + スキル常時注入」は、怠惰キャラに限らず、あらゆるチーム固有ルールに転用できます。まずは自分のプロジェクトで、毎回手で貼り付けている指示が何かを洗い出すところから始めてみてください。それこそが、フックに移すべき最初の候補です。
チームでのAI活用の設計や、開発そのものの相談が必要になったときは、弊社のAI導入支援・開発支援もあわせて検討してみてください。
additionalContext の仕様



